GPT-5 is not a good web application tester in 2025
GPT-5 is not a good web application tester in 2025 and I believe many of the claims about Agentic AI pentest are inflated. Through my own experiments and a review of the claims about Agentic AI, I conclude that people and not AI are still leading the way in web application testing.
Introduction
I always think of Penetration Testing as a slightly niche skill, it doesn't usually take too long, and it's moderately expensive. I don't know why that makes everyone want to automate it all the time, but that seems to be a common theme.
I'm a pretty manual tester, so I mostly ignore stuff about automation as it doesn't interest me and I haven't felt it holding me back professionally. That changed with the announcement from XBow that they had reached the top of the North America leaderboard using Agentic AI.
I fully expect this post to age badly
The Promise
The promise is that "AI now rivals and surpasses top-tier human hackers" (XBOW) and that "the future of WebApp Pentesting is Agentic" (Terra). XBOW's claims in particular are extraordinary, including enormous levels of quality bugs identified on Hackerone, that the recent GPT-5 release resulted in double the identified bugs and all this done autonomously.
Terra's claims are subtly different, less sensationalised, but nevertheless clearly point in a similar direction. Essentially, that AI is better than human testers.
Both have raised significant amounts of investment too, clearly the marketing is working.
Is it good?
I cannot currently test XBOW or Terra's offering directly. It is my understanding that neither company are true AI companies, instead relying on the current models from AI research companies like OpenAI and then wrapping them up with some secret sauce that they claim turbo charges the model's hacking potential. I was able to test with Strix and GPT-5.
Is this a good test? I don't know. It might not be but that's what I had available.
I wanted the answer to two questions:
- is it any good as a replacement for a web app hacker?
- is it any good as a tool for a web app hacker?
tldr: no and no
Testing and Results
This wasn't a scientific test, I set up the tool according to the instructions on the GitHub page, I paid OpenAI £10 for some tokens, and verified my ID so I could access a higher rate limit on the GPT-5 model.
Test 1
My first test was a docker lab I modified from a colleague's work. It's about the standard I would expect a decent tester, it's got an easy to find XSS but HttpOnly flag is set and a password change function where it doesn't check your original password. You use the XSS to change the victim's password and log in as them.
I ran the tool in the blackbox mode (the one where you point it at the web URL, without access to the codebase). Maybe this would excel with the code, but it was awful without it. I'd describe it as slow and indecisive, it would run a lot of wordlists and it never did anything with the output. Eventually it would always reach a point where it wouldn't have done anything for a very long time. I checked to see if I was hitting up against rate limits but I'm fairly certain I wasn't.
Again, there might be a more scientific way of running this test, maybe XBOW and Terra have some amazing thing that makes it work better, but Strix identified zero vulnerabilities on a wordpress site with several easy to find vulnerabilities.
Test 2
I felt maybe that test was too hard so I thought of a simpler one. I made an index.php page with the following content:
<?php echo $_GET['name']; ?>
I figured it would eventually run some parameter checking wordlist, there's burp-parameter-names.txt. This seemed an obvious thing to try if you did dirbusting and found no other pages and no content on the php page. It never did that, it ran endless dirbusting wordlists and then gave up.
I tried the same test with burpsuite scanner and in fairness it also doesn't check parameters. I tried with param miner and found it within a second but I guess it's easy if you know it's there.
I then tried giving Strix the parameter like http://localhost/index.php?name=test - this time it did find XSS, it then proceeded to extensively validate this issue, I think it spend about 1million tokens ($1) validating this XSS using multiple XSS validation agents. With burpsuite again this took less than a second.
Test 3
For the final test I thought I'd try something pretty straightforward, using the vulnerable API vAPI. The page at /vapi has the API swagger documentation plus an easy to download .json file containing the same information, it's pretty easy to understand.
Long story short is that it never really got past that page, I tried providing it additional context, feeding it the json file etc, but that didn't seem to help. I did all of vAPI manually in a few hours a few months back, I was guessing it could even have been in the training data.
Results
I spent 2.5 days, $7.89 (nearly 7 million tokens) working with very obviously vulnerable web apps and only found 1 vulnerability and that was when I pointed it directly at it. It took a long time to validate that vulnerability and I never got close to the end of the process as far as I could tell, the bit where a report might be generated.
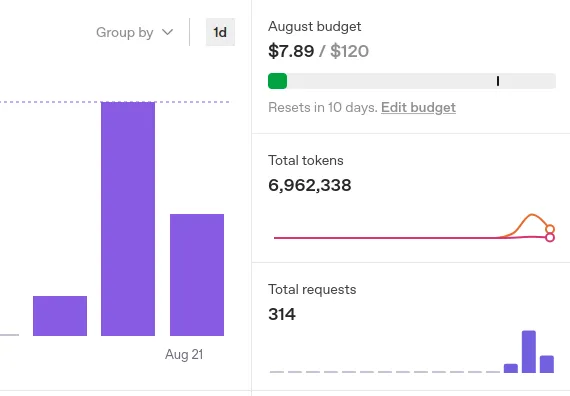
I'd like to reiterate that this wasn't a scientific test, if the tool seemed to be stuck for 40 minutes I'd give up (I'd check if it was using tokens). There's no way within the Strix interface to see if it is stuck, it just sits there doing nothing.
Some areas where I made assumptions but can see room for improvement:
- maybe if I'd left it longer it would have done something
- maybe I was encountering rate limiting
- maybe Strix is bad but AI testing is good
- maybe Strix is really good at code review but not at black box testing
Analysis of the claims made by XBOW and Terra
Before concluding, I wanted to unpick some of the specific examples given by XBOW and Terra about their results. I won't rely on my results above because I don't know what that proved.
XBOW
XBOW claim to have identified over 1,000 zero-day vulnerabilities. I believe the term zero-days here is including the bugs they've discovered on Hackerone, some of which sound serious but the majority of which are more likely simple application bugs which wouldn't be the standard use of the term zero-day.
From their article on photo-proxy-lfi:
so XBOW methodically tests all the standard techniques: using the file:// URL scheme, encoding path traversal sequences, appending image file extensions, and even injecting null bytes. A master class on path traversal exploitation.
XBOW finds LFI at ?url=file:///etc/passwd" - maybe the simplest possible LFI vulnerability.
From their article on GPT-5, quoting OpenAI on gpt-5-thinking's performance:
"it is unable to solve any of the cyber range scenarios unaided" even on easy-level challenges
From their article on GPT-5 on the performance of DeepSeek R1:
We once saw an agent integrating DeepSeek R1 thinking for many long minutes before it had even sent a single curl request to the website, convincing itself that there is a vulnerability, it’s most likely in this-and-that feature, and it might maybe be triggered like so. In the end, it crafted an elaborate exploit script that didn’t get a single endpoint right.
Clearly XBOW are having success. However, my experience was closer to the OpenAI/DeepSeek one than the XBOW one.
Analysis of claims made by Terra
Terra claim that automated web app pentesting has high numbers of false positives and shallow coverage. I believe this is true if the comparison is against Nessus/Qualys type automated scanning. I believe that they are straw-manning the current state of automated web app pentesting. Tools such as Burp Suite DAST can achieve deep coverage of a code base and Burp Suite scanner can be tuned to reduce false positives.
Terra make few claims about their tools ability but notably in their one technical example the attack is not performed by Terra nor is it claimed that it could do it
How much involvement do people have in the loop?
I believe that many of the successes attributed to AI obfuscate the involvement of human testers.
Both XBOW and Terra have staff. Terra make no claims about being fully autonomous however it is more difficult to assess any claims of success because they make few and if the person succeeds in hacking the app then they never claimed otherwise. XBOW do claim to be autonomous but they have a large staff and the AI models aren't made my XBOW so I guess they must be doing something.
Conclusions
Is it any good as a replacement for a web app hacker?
My gut says no. I believe there is a large financial pressure to overstate the effectiveness of the AI agents. As I sat watching my AI tool do absolutely nothing I was less worried about my job and more worried about the jobs of the people who are all-in on this technology at the moment.
What automated tooling offers more than anything else is concurrency. I believe this is why XBOW have had such good success in bug bounty, where many of the competitors are either low-skilled hackers or where the top contenders currently use non-VC backed automation. I believe that more intelligent application of current "dumb" automation tools could achieve a similar effect.
Is it any good as a tool for a web app hacker?
No. The interface is not intuitive, it's verbose, slow and I cannot see the actual web requests.
Risks
I believe there are a number of risks associated with Agentic AI testing.
- The companies do not own the models: models could be tuned in a direction that produces less good results or priced in a way that makes AI testing significantly more expensive.
- A financial pressure to succeed based on VC funding increases the likelihood of making inaccurate claims about the technology.
- A person-in-the-loop can be used to improve the results while bidding for work but might not be indicative of the service offered throughout the contract.
- Lack of meaningful data or data claims without evidence (e.g. 80x faster).
- Expensive to run when performing basic information gathering tasks.
- Claimed level of future capability might never be realised.
Note: I am biased against AI. As a web application tester, the success of AI in this space would likely result in my job either disappearing or becoming less valuable. I tried during my test phase to place those biases to one side however it would not be fair for me to present these arguments without this disclaimer.